埃隆·马斯克开源Grok的“难言之隐”与“野望”[size=1em]腾讯科技[size=1em]03-18 16:22
2024年3月18日,马斯克兑现前几天的诺言,正式对Grok大模型进行开源。根据开源信息显示:Grok模型的Transformer达到64层,大小为314B;用户可以将Grok用于商业用途(免费),并且进行修改和分发,并没有附加条款。 首先速览一下 Grok 的参数细节: ①模型概况:拥有3140亿个参数,成为目前参数量最大的开源模型;Grok-1 是一个基于 Transformer 的自回归模型。xAI 利用来自人类和早期 Grok-0 模型的大量反馈对模型进行了微调。初始的 Grok-1 能够处理 8192 个 token 的上下文长度,已经于 2023 年 11 月发布。 ②特点:模型采用了混合专家架构,共有8个专家模型,其中每个数据单元(Token)由2位专家处理。这使得每次对Token的处理会涉及860亿激活参数,比目前开源的最大模型Llama-2 70B的总参数量还多。模型包含64个处理层,模型使用了48个用于处理查询的注意力机制单元和8个用于处理键/值对的注意力机制单元。模型支持8bit精度量化。 ③缺陷:Grok-1 语言模型不具备独立搜索网络的能力。在 Grok 中部署搜索工具和数据库可以增强模型的能力和真实性。尽管可以访问外部信息源,但模型仍会产生幻觉。 ④训练数据:Grok-1 发布版本所使用的训练数据来自截至 2023 年第三季度的互联网数据和 xAI 的 AI 训练师提供的数据。 再看一下各项基准测试的评分对比: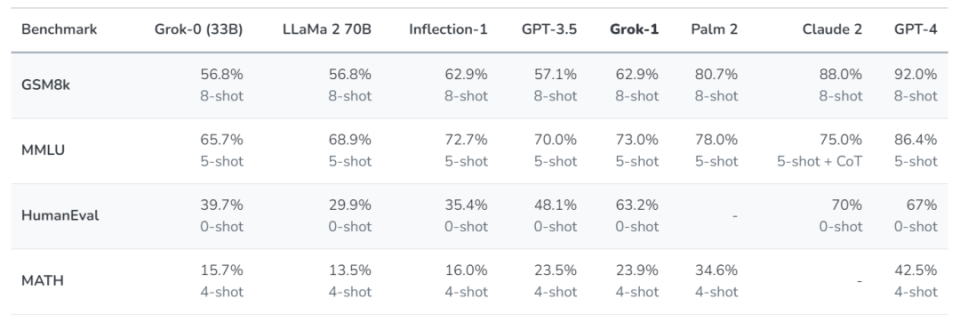 从评分上来看,没有什么惊艳之处,比不过GPT4,也比不过Palm-2及Claude3。但是xAI 表示,他们没有为应对这个考试而特别准备或调整模型。也许我们可以小小期待一下,Grok1.5 是不是会带来某些惊喜。 这次公布的开源版本,马斯克绝对会着重讽刺一下隔壁的“Closed AI”。 但是,Grok 开源,仅仅是为了讽刺 OpenAI 吗?如果坚持闭源,Grok 是不是会把自己陷入某些比较艰难的境地?大模型开源 VS 闭源,在产业生态上,分别占据什么样的位置? Grok开源的难言之隐马斯克宣布xAI开源,虽然引发了新一轮的创新竞争和争议,但从整个市场格局来看,Grok的开源也是不得已而为之的决定。 Grok是马斯克创立的AI公司X.ai推出的大模型,相比于其他大模型,Grok的与众不同之处在于使用了X平台(原名Twitter)上的语料进行训练,据称Grok还自带幽默感和怼人的风格。 虽然得到了X平台数据资源的加持,但是在大模型大爆发的当下,Grok并没有进入第一梯队。 尤其是2024年以来,Gemini、Claude3接连发布,其能力已经接近甚至超越GPT-4,三者处于第一梯队的行业格局基本确定。这还不算上Mistral AI和Inflection AI的奋起直追。因此,未来的基座大模型“虹吸效应”越发明显,留给其他玩家的机会并不多。 Grok借助埃隆·马斯克的影响力虽然得到了一定的关注度,但是在产业和用户的知名度并不高,在大模型的“军备竞赛”中并没有太多竞争优势。抛开马斯克本身与OpenAI的恩怨情仇,Grok继续叫板的意义并不大。 如果Grok继续走闭源开发的路径,基本上将成为人工智能时代的“诺基亚塞班系统”,被抛弃只是时间问题。届时Grok既不能帮助马斯克对X平台实现商业化变现,又成为昂贵的沉默成本。 因此,与其作为一个二流甚至三流的闭源大模型,倒不如破釜沉舟,通过开源为Grok杀出一条血路,在风口上为Grok谋下新的发展路径。国内大模型月之暗面CEO杨植麟也曾表达过,“如果我今天有一个领先的模型,开源出来,大概率不合理。反而是落后者可能会这么做,或者开源小模型,搅局嘛,反正不开源也没价值。” 开源是推动产业“螺旋式成长”的必要一环技术的发展有闭源,就必然有开源。闭源和开源两者的性能会竞相追赶,交替上升,这也是技术发展的动力之一。 移动互联网时代iOS的和Android就是闭源和开源的典型代表,因此不存在闭源一直碾压开源的现象,而是双方在不断借鉴和切磋的过程中,让更多用户在移动互联网时代获得更多收益,成果惠及社会。 同样道理,在大模型时代,如果说ChatGPT点燃大家对大模型的热情,那么开源大模型的出现则是进一步降低了创业者的门槛,让更多创业者在基础模型方面处于同一起跑线上。 甚至可以说,正是因为有了开源大模型才极大降低了大模型的开发成本。毕竟仅靠OpenAI一家公司是难以将大模型向全球生态的形态进行发展,大家也不愿意看到一家独大的局面。 例如2024年年初火爆的文生视频模型Sora引发全球轰动,业内也不短加快开源版本的研发,国内研究机构甚至推出了Open-Sora框架,并将复现成本降低46%,模型训练输入序列长度扩充至819K patches,让更多机构可以在文生视频利于获得可用的工具和方法。 同时,在企业应用大模型时,不仅关注模型的前沿能力,还需考虑数据安全隐私、成本控制等多方面因素。因此,面向企业的开源模型在许多情况下更能满足企业个性化需求,而像OpenAI这样的闭源模型公司可能无法完全满足这些需求。 未来的大模型市场,将呈现出开源模型满足基本智能需求,闭源模型满足高阶需求的互补态势。 开源基础上的创新,次啊是“真功夫”对于大模型而言,开源的底座只是起点,需要在这个起点上进一步创新。 尤其是当前开源大模型更新的速度不断加快,今天可能还是业内最好的模型,但是明天就有可能被超越,变成沉默成本。当模型迭代速度不断加快的今天,过去的投入很有可能就会打水漂。 因此在开源底座的基础上,做为我所用的东西更有价值。比如目前海外的开源模型发展较快,但是其模型中文能力一般,也没有丰富的行业场景,缺乏国内如此丰富的数据预训练资源,这反倒是创业的机会和宝贵的窗口期。 同时,开源模型让更多高校、科研机构、中小企业不断深入使用,并对开源模型进行不断完善改进,最终这些成果也将惠及参与开源模型的所有人。 以Meta公司开源的LLaMa2为例,截止2023年底,HuggingFace上开源的大模型排行榜前十名中,有8个是基于LLaMa 2 打造的,使用LLaMa 2的开源大模型已经超过1500个。同时,Meta、英特尔、Stability AI、Hugging Face、耶鲁大学、康奈尔大学等57家科技公司、学术机构还在2023年下半年成立了AI联盟,旨在通过构建开源大模型生态,来推动开源工作的发展。目前AI联盟构建起从研究、评估、硬件、安全、公众参与等一整套流程。 当然,依托开源做研发并不容易,用好开源模型也是一种壁垒和门槛。 这是因为基于开源模型做开发,其后续的投入门槛并不低,对研发要求依旧很高。用开源模型做底座只是有效降低了冷启动的成本,具体来看:优秀的开源模型可能已经学习超过万亿token的数据,因此帮助创业者节省了部分成本,创业者可以在这个基础上进一步进行训练,最终将模型做到行业领先水平,这个过程中数据清洗、预训练、微调、强化学习等步骤都不能少。 “开源+”战略或将成为Grok突围的新思路1.开源+端侧实现“软硬一体化” 当前,主流大模型动辄万亿级的参数,需要海量的算力资源予以支持,但并非所有终端都能够支持这样的成本投入,而在智能手机、物联网等端侧需要小巧、灵活的轻量级模型,甚至可以在终端处于离线状态也能够使用。 因此,真正做到让AI可以“触手可及”,端侧模型落地具体需求场景更为迫切: 埃隆·马斯克在特斯拉汽车、星链卫星终端、甚至擎天柱机器人正在构建AI落地“最硬核”场景:特斯拉的Autopilot使用了AI算法来实现自动驾驶功能,将是未来智慧交通的一种重要尝试;SpaceX最近发射的星舰实现了2秒内处理所有33个发动机的数据,并且确保可以安全加速。未来基于Grok来构建软硬一体化的模型-应用生态体系,有望解决当前“基础模型和需求场景,谁来把两者衔接起来”的现实问题。更为关键的一点在于,大部分目前致力于大模型开发的公司最终将变为模型-应用一体化的企业,而且应用层的市场价值更大。 一旦通过了TMF(Technology Market Fit)、PMF(Product Market Fit)阶段,其价值将在生产力效率提升、泛娱乐、信息流转创新方面产生更大效益,而马斯克在其他产业的布局可以更好的与之发生“共振”:一方面通过Grok开源,吸引更多用户和企业的调用和接入,提升通用的智能化能力,另一方面围绕自身生态和产业场景、数据方面的优势(汽车+卫星+机器人)构建更多可落地的创新。生成式人工智能正在从超级模型向超级应用转型的新起点,与其和学霸“卷”基座大模型,不如在应用侧让Grok率先卡位。 同时,对于一直尚未进入大众视野的“大模型安全和透明度”问题,Grok的开源有望为大众理解大模型复杂性和安全挑战,提供新的视角。毕竟以目前的发展速度,大模型已经不是技术研发问题,而是一个全社会需要广泛参与和讨论的社会话题。 2.开源+闭源构建“一体两翼” 是的,开源和闭源并非死对头,老死不相往来。 事实上,在大模型领域大量科技企业已经在探索开源+闭源的双重策略。例如谷歌在发布大模型Gemini的时候,能力较为强大的Gemini Ultra是采用闭源策略,主要竞争对手是GPT-4、Claude3.0等,而Gemma2B和7B则采用了开源战略,能力稍逊一筹,但是在特定场景将有着更广泛的应用领域。 Grok可以借鉴开源与闭源混搭的思路,以“半开源”的方式一方面释放能力给更多用户和企业,另一方面借助X平台的海量优质实时数据构建自身壁垒。从而在大模型的竞争中获得一席之地。 当然并不是说开源大模型可以解决一切问题。事实上,开源大模型和闭源大模型还是有一定的差距:闭源大模型整体能力上还是高于开源模型。因为开源的大模型大多还没有经过算力验证,闭源是人才密度、资金密度、资源密度高度集中的方式,同时开源本身也避免不了中心化的风险。 对于企业来讲,希望在基座大模型上实现反超的机会已经接近尾声,但是通过选择开源模型是更加务实的选择,优化、训练出实用的模型更是真本事。基于开源,是有机会作出优秀的大模型,核心是能够拥有相对领先的认知,可以对模型能力进行持续迭代。 本文作者:翟尤,本文来源:,原文标题:《埃隆·马斯克开源Grok的“难言之隐”与“野望”》
| 

 发表于 2024-3-19 10:15
发表于 2024-3-19 10:15
 楼主
楼主
